欧洲杯体育Fail;换个桌子高度-亚博全站APP登录 亚博登录网址|首页

金磊 发自 杭州
量子位 | 公众号 QbitAI
从3000小时到整整20000小时。
真确寰宇数据里的Scaling Law,平直喂出了个最强VLA(Vision-Language-Action)基座模子!

这就是蚂蚁灵波今天开源的具身智能基座模子——LingBot-VLA。
为什么说它是面前最强?先看数据。
从“20000小时”这个量上来看,LingBot-VLA依然解锁了迄今为止开源的最大领域真确机器东说念主数据之一。
而况性能亦然够打,在泰斗评测中也全面超过了此前公认最强Physical Intelligence的π0.5,以及英伟达GR00T N1.6等一众国外顶尖模子。
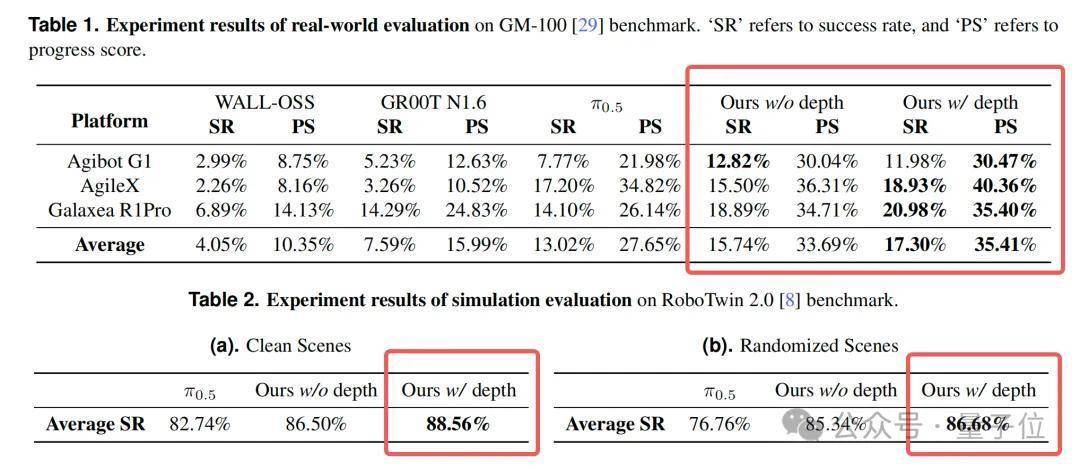
再看实验弘扬。
此前具身智能圈子一个很头疼的问题,就是一朝环境发生变化,VLA就不太好使了:
换了个机器东说念主,Fail;
换了个摄像头,Fail;换个桌子高度,Fail……但在LingBot-VLA加持下的机器东说念主,脑子一下子就变贤达了,学会了见招拆招。
举例面临复杂的收纳操作——把桌面物体放进包里并拉上拉链,机器东说念主双手各司其职,动作一气呵成:
视频地址:https://mp.weixin.qq.com/s/5d_nTy6YnkHJqA0C0QIOdQ
更复杂极少的餐具清洁整理——配合多种用具完成餐具清洗并归位,不错看到,机器东说念主依旧是能精确拿捏多样万般的物体。
即即是像透明玻璃杯这么时常让机器东说念主看不清的物体,它也能简约hold住:
视频地址:https://mp.weixin.qq.com/s/5d_nTy6YnkHJqA0C0QIOdQ
而况一样的任务,因为有了一个贤达的脑子,无论是放在AgileX、AgibotG1如故Galaxea三个不同的机器东说念主身上,都备都能治丝而棼:
视频地址:https://mp.weixin.qq.com/s/5d_nTy6YnkHJqA0C0QIOdQ
而纵不雅整项照看,除了数据性能和实验弘扬以外,更重要的极少是,LingBot-VLA还指明了一条通用具身智能发展旅途:
从3000小时到20000小时,初度在真确寰宇场景中,系统性地考据了VLA模子性能会跟着数据领域扩大而络续培植的Scaling Law。
而况是在20000小时之后,性能培植还莫得失效的那种。
正如网友转头的那般:
更多真确数据 → 更高见效用 → 还未达到鼓胀。
一个大脑,多个肉体,这就是领域化之说念。
那么LingBot-VLA具体又是如何终了的?咱们连接往下看。
主打一个真确在谈LingBot-VLA是若何真金不怕火成的之前,咱们还需要先了解一下机器东说念主的窘境。
之前像Physical Intelligence的π系列这么的顶尖VLA模子,一个很大的问题就是,它们预考研的数据精深依赖仿真环境。
仿竟然公正是资本低、可并行,却与真确物理寰宇的质感存在难以弥合的鸿沟。
打个譬如,一个机器东说念主在仿真环境里能丝滑地叠穿着,但到了真确寰宇里可能连个衣角都抓不稳。
因此,蚂蚁灵波团队的遴荐是这么的:仿竟然不好使,那就全部给与真确寰宇的机器东说念主操作数据。
从2023年泉源,他们协调星海图、松灵机器东说念主等伸开合作,在一间间真确的实验室里,通过遥控操作的形状,让机器东说念主完成千千万万次抓取、舍弃、拼装等动作。
数据领域从最初的3000小时,全部彭胀到20000小时,全部源自物理寰宇。
而况这些数据并非来自单一机器东说念主。
照看团队动用了9种不同品牌和构型的双臂机器东说念主,包括AgileX、Agibot G1、Galaxea R1Pro/R1Lite、Realman Rs-02、Leju Kuavo 4 Pro、青龙机器东说念主、ARX Lift2以及Bimanual Franka。
这意味着,模子从“小时候”泉源就眼光了不同机械臂的通达形状、不同摄像头的视角、不同夹爪的特色。
这种数据的异构性和丰富性,成了LingBot-VLA具有很强泛化材干的基础。
为了将这些海量视频数据改造为模子可学习的课本,团队还给与了一个奥妙的半自动标注经过:
东说念主工将多视角视频按原子动作拆分红片断;期骗广宽的视觉说话模子Qwen3-VL-235B,为每一段视频生成精确的当然说话描述,举例“用左手夹爪网络红色积木”、“将水杯幽静地放入微波炉”。最终,这20000小时、涵盖无数原子动作的多模态数据,组成了LingBot-VLA的养料。
除了海量真确数据以外,模子架构上的翻新,亦然LingBot-VLA的重要所在。
它给与了一种名为群众搀和Transformer的架构,不错将其融会为为机器东说念主假想了一套大脑与小脑协同责任的系统:
大脑:一个依然过预考研的广宽视觉说话模子。LingBot-VLA选用了Qwen2.5-VL。它的职责是进行高级次的语义融会——不雅察环境(多视角图像),理奉命务教导(当然说话),并想考出现时景色和任务地方。小脑:一个特意开动化的动作群众模块。它的职责是接受来欢欣脑的语义信息,勾通机器东说念主现时的自己状态,打算并生成具体、都集、可推论的动作序列。而且二者之间并非是各玩各的,它们通过一个分享的自驻防力机制进行深度耦合,终表露在模子每一层的信拒却互。
在动作生成手艺上,LingBot-VLA还抛弃了传统的糟塌瞻望,引入了先进的流匹配模子。
简单来说,它不再瞻望“下一步要津应该转若干度”这么一个具体的点,而是学习通盘动作变化的平滑流场。
这使得机器东说念主产生的动作愈加丝滑、连贯,更接近东说念主类演示的当然度,关于需要致密截止的长序列任务至关热切。
除此以外,深度感知,是另一个手艺上的点睛之笔。
为的就是让机器东说念主不仅看得见,还能感知距离——引入了自研的LingBot-Depth深度测度模子提供的深度信息。
也就是昨天蚂蚁灵波开源的让机器东说念主能看清透明和反光物体的新手艺。
这种门径通过一种可学习的查询对都手艺,将深度信息蒸馏注入到VLA模子的视觉融会中。
特地于让机器东说念主赢得了对三维空间的直不雅感知材干,使其在面临“将芯片插入窄小卡槽”、“幸免抓取时碰撞杯壁”等需要精确空间磋商的任务时,弘扬大幅培植。
然则,要将20000小时高维度的视频和动作数据考研成一个模子,对算力是恐怖的耗尽。
蚂蚁灵波团队对此的修起是:对考研基础模范进行系统级优化,打造了一个高性能开源代码库。
他们在辞别式计策、算子级别和数据处理管说念上进行了全地方校正:
给与完全分片数据并行计策,极致优化GPU内存占用。针对动作群众模块假想特定的分片组,大幅缩小通讯支出。期骗FlexAttention等手艺对寥落驻防力策动进行加快。后果是立竿见影的。
在8卡GPU的树立下,LingBot-VLA代码库终表露每秒每GPU 261个样本的蒙胧量;与社区主流的OpenPI、StarVLA等框架比较,考研速率培植了1.5倍至2.8倍。
以往需要一个月完成的实验,面前可能只需一到两周就能措置了。
这不仅大大缩小了科研翻新的周期和资本,更热切的是,它让基于万小时级真确数据迭代VLA模子,从此变得可行。效用的培植,是解锁数据缩放定律的前提。
100个任务,22500次的全面测试模子好不好,不可只在论文里说。
为此,蚂蚁灵波团队在泰斗的评测体系作念了测试——GM-100基准。
这一测评集是由上海交通大学等机构协调研发,旨在为估量机器东说念主大脑(智能模子)与肉体(物理推论)的协同材干,提供一个更系统、洞开且可复现的评估基准。
它包含100个从易到难的致密操作任务,简约单的“抓取积木”,到复杂的“制作三明治”、“叠放穿着”。
评测在Agibot G1、AgileX和Galaxea R1Pro三种真确机器东说念主平台上进行。
每个模子在每个任务上都要进行多轮测试,共计产生了22500次真确机器东说念主测试摄像。通盘摄像均已开源,确保了评测的完全可复现和透明。
在这场同台竞技中,LingBot-VLA迎来了三位分量级敌手:π0.5、英伟达的GR00T N1.6,以及WALL-OSS。
通盘模子都在探究的数据、探究的超参数下进行后考研,以确保公正比较。
在详细了任务见效用和程度得分两项中枢地方后,LingBot-VLA(无深度版块)已在三名堂标上全面率先WALL-OSS与GR00T N1.6。
而会通了深度信息的LingBot-VLA,则在三名堂标上均权贵超过了面前公认的强基准——π0.5。
举例,在AgileX平台上,LingBot-VLA(含深度)的平均任务见效用达到了18.93%,而π0.5为17.20%;在更具挑战性的Galaxea R1Pro平台上,上风一样显著(20.98% vs 14.10%)。
在仿真基准RoboTwin 2.0上,上风依旧显著。
在物体位置、布景、灯光高度当场化的复杂场景中,LingBot-VLA比较π0.5取得了近10个百分点的透澈见效用培植。
这解说其学到的材干是鲁棒的、可泛化的,而非对特定环境的过拟合。
更热切的是,照看团队通过截止预考研数据量(从3000小时到20000小时)进行的实验澄澈标明:
跟着真确寰宇数据量的加多,模子不才游各项任务上的性能呈现络续、分解的培植,且尚未看到鼓胀迹象。
不造机器东说念主,但要搞个贤达大脑
临了,来谈一谈蚂蚁灵波要作念的事情。
与现时机器东说念主行业存在的一个核肉痛点息息有关,即场景碎屑化与硬件非标化。
不同的机器东说念主实验,要津构型、传感器树立、驱动形状天渊之别。传统的解决形状是为每个场景、每种硬件定制援手算法,资本高、周期长、难以复制。
LingBot-VLA提供的是一种通用智能基座想路,也就是不作念机器东说念主的实验,但求作念一个通用大脑:通过在海量异构真确数据上预考研,模子学会了进步不同硬件平台的、本质性的操作逻辑和物理融会。
就像一个学会了“抓抓”本质观念的东说念主,非论给他筷子、夹子如故机械爪,他都能通过简单符合掌抓使用门径。
LingBot-VLA展示的跨实验泛化材干恰是如斯。
模子在9种机器东说念主数据上预考研后,在3种未见过的机器东说念主平台上依然弘扬优异,解说了其材干并非绑定于特定硬件。
这为终了 “一次考研,多端部署” 的领域化落地愿景提供了坚实的手艺基础。
为了缩小行业的使用门槛,蚂蚁灵波团队不仅开源了模子和代码,还孝敬了 “交钥匙”式的评估基准和高效后考研决策:
可复现的评估:GM-100基准与全部22500次测试摄像开源,缔造了行业评测新模范。低资本后考研:高效的代码库与数据高效性上风(实验骄傲,仅用敌手60%的数据量就能达到更好后果),让企业能用更少的数据、更低的算力资本完成对特定场景的适配。遥想2024年,π0的开源固然引爆了群众VLA的照看飞扬,但它主要基于仿真数据,在真机落地上存在局限。
而LingBot-VLA的价值在于,它初度提供了一个基于万小时级真机数据开源的全栈解决决策,鼓吹行业从实验室演示迈向可领域化落地的新阶段。
要是说蚂蚁灵波LingBot-VLA是一个单点,那么它所隐射的是蚂齐集团在通往AGI探索的手艺旅途与行业愿景:
蚂蚁百灵:当作底层基础大模子,提供通用的说话与逻辑材干基石。蚂蚁灵光:面向应用的通用AI助手,探索AI的交互与处事界限。蚂蚁灵波:恰是本文主角,专注攻克具身智能,旨在为物理寰宇中的智能体赋予大脑。从基础大模子到多模态,再到如今的具身智能,蚂蚁的AGI拼图正在一块块补全。
这条路,注定是漫长且需要生态协调的。但当行业率先者泉源体系化布局,并主动拆掉围墙,巧合正如他们所期待的那样——阿谁属于通用东说念主工智能的改日,会以更洞开、更协调的形状,更早地到来。
巧合在不久的将来,东说念主们的生计就会变得像《连线》杂志所说的那样:
你的第一个机器东说念主共事,草率率是个“中国东说念主”。
名堂主页:
https://technology.robbyant.com/lingbot-vlaGitHub:
https://github.com/robbyant/lingbot-vla模子权重:
https://huggingface.co/robbyant/lingbot-vlahttps://www.modelscope.cn/collections/Robbyant/LingBot-VLA— 完 —
量子位 QbitAI · 头条号
抠门咱们欧洲杯体育,第一时辰获知前沿科技动态